レコード管理
最終更新: 2022年02月09日
概要
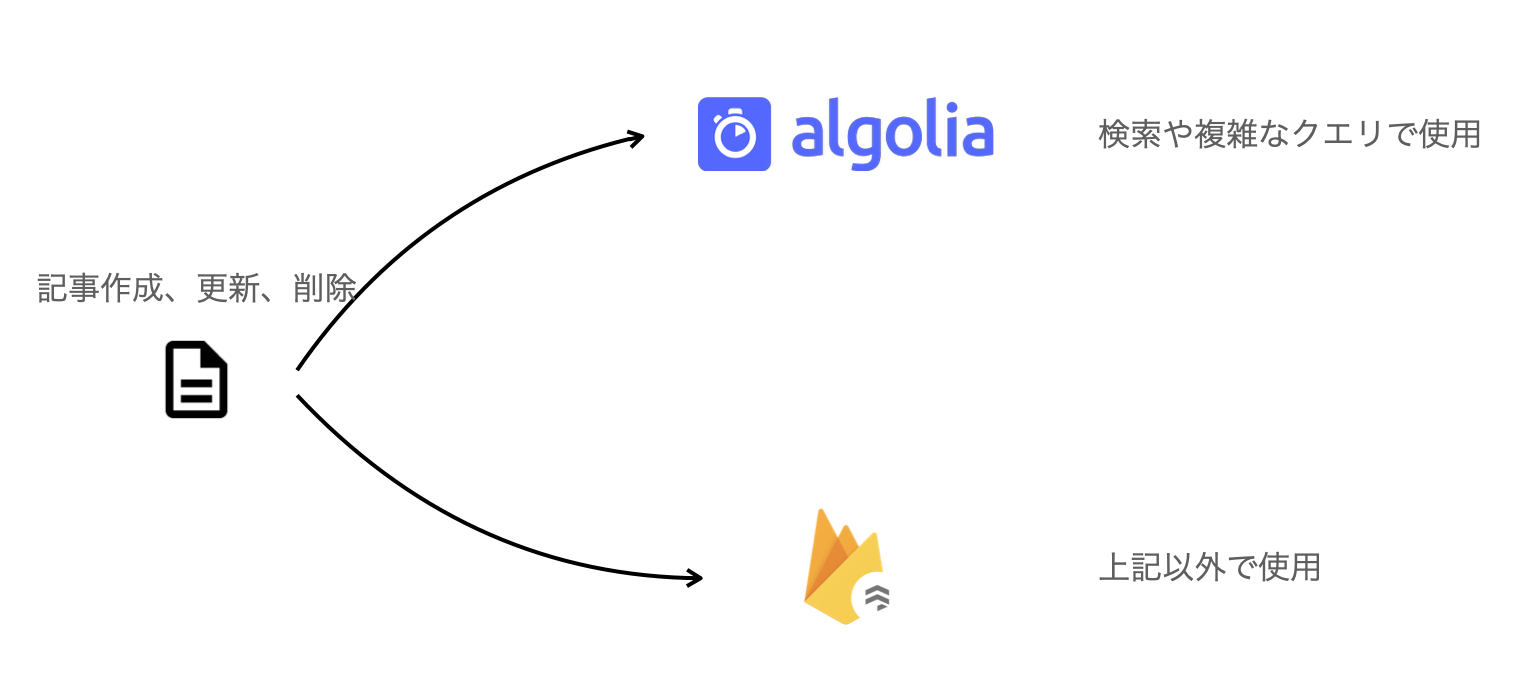
レコード管理は Admin API Key を使いますが、Admin API Keyが漏れると好きなようにレコードを操作されてしまうためレコード管理はサーバーサイドで行います。Next.js の API か Firebase Cloud Functions で行います。
なお、AlgoliaはFirestoreに比べて参照コストが高いため検索や複雑なクエリなど、どうしてもFirestoreで対応できない場合にのみ使用しましょう。AlgoliaとFirestoreに同期的に同じデータを持たせておき、状況に応じてAlgoliaからデータを参照するか、Firestoreからデータを参照するか決める形になります。
Next.js API vs Firebase Cloud Functions
Cloud Functionsは実行速度が極めて遅いため即応性が重要な場合Next.js APIを使いましょう。たとえば記事投稿直後にただちに検索にヒットさせたい場合は Next.js API が良いでしょう。
ただしNext.js API の場合URLを知っていれば誰でもAPIを呼び出せてしまうため、API側でユーザー認証を行い、不正なリクエストを防ぐ実装が別途必要です。
Firebase Cloud Functions の場合認証しているユーザーからのみ関数呼び出しを許可する方法があるため、Next.js API を使う場合に比べて実装はシンプルになります。
状況に合わせてどちらを使うか判断してください。
Indiceの作成
ダッシュボードからIndiceを作成してください。今回は記事投稿用に posts という名前で作成します。Indiceは複数形の名前に統一することをお勧めします。
Next.jsのAPIでデータを追加する
Next.jsのAPIの動作速度はホストするサーバー次第ですが、少なくともFirebase Cloud Functionsよりは早いことが多いでしょう。そのため、投稿したデータがすぐに検索結果に反映されてほしい場合Next.js APIからレコード追加しましょう。
逆にすぐに検索結果に反映される必要がない場合は後述するCloud Functionsによるレコード追加がお勧めです。
実装例
pages/edit.tsxconst EditorPage = () => { const {handleSubmit, register, reset} = useForm(); const savePost = (data) => { // Firestoreにデータを追加 const id = doc(collection(db, 'posts')).id; // 記事IDを生成 const ref = doc(db, `posts/${id}`); const post = { id, ...data } setDoc(ref, post) // Algoliaにデータを追加 const token = await getIdToken(auth.currentUser!, true); // auth = getAuth(); fetch('/api/article', { method: 'POST', headers: { 'Content-Type': 'application/json', Authorization: 'Bearer ' + token, // ログインユーザーの認証トークンを渡す }, body: JSON.stringify(data) }) reset(); } return ( <form onSubmit={handleSubmit(savePost)}> <input type="text" {...register{'title'}} /> <textarea {...register{'body'}} /> <button>送信</button> </form> ) } export default EditorPage;
api/post.tsimport { getAuth } from 'firebase-admin/auth'; import { NextApiRequest, NextApiResponse } from 'next'; const client = algoliasearch( process.env.NEXT_PUBLIC_ALGOLIA_APP_ID as string, process.env.ALGOLIA_ADMIN_KEY as string ); const postIndex = client.initIndex('docs'); // レコードを作成 export const savePostRecord = async (data) => { return postIndex.saveObject({ ...data, objectID: data.id }); }; // レコードを削除 export const deletePostRecord = (id: string) => { return postIndex.deleteObject(id); }; const handler = async (req: NextApiRequest, res: NextApiResponse<string>) => { // ログインユーザーの認証トークンを取得 const token = req.headers.authorization?.split(' ')?.[1] as string; try { // 認証トークンを検証 await getAuth().verifyIdToken(token); } catch (error) { return res.status(500).send('error'); } try { switch (req.method) { case 'POST': await savePostRecord(req.body); break; case 'DELETE': await deletePostRecord(req.body.docId); break; } res.status(200).send('success'); } catch (error) { console.log(error); res.status(500).send('error'); } }; export default handler;
Cloud Functions でレコードを追加する
Cloud Functions を使う場合、大きく二つのパターンがあります。
- 呼び出し型関数で任意のタイミングでレコードを追加する
- トリガー関数で自動的にレコードを同期する(拡張機能を使うか、自分で作成する)
トリガー関数の場合Firebase拡張機能を使えばノーコードで実装することができますが、レコード追加時にデータを加工したい場合拡張機能では対応できません。
いずれの場合も初期化時にAdmin API Key を使うため環境変数にセットしておきましょう。
firebase functions:config:set algolia.id="APP ID" algolia.key="Admin API Key"
Algoliaの環境が開発用と本番用など複数ある場合、それぞれのFirebase環境にそれぞれの環境変数をセットしてください。
トリガー関数とは
トリガーとは「きっかけ」を意味します。何らかのきっかけで実行される関数をトリガー関数を呼びます。たとえばデータが追加、削除、更新されたタイミングで自動的に実行される関数は代表的なトリガー関数です。
ある時間が来た時に発動する関数もトリガー関数と言えますが、Firebaseのドキュメントにおいては関数のスケジュール設定とし表現されています。
呼び出し型関数を使う
呼び出し型関数の場合サーバーサイドはNext.js APIと同じ実装になりますが、ログインユーザーの認証は不要になります。
functions/index.tsimport algoliasearch from 'algoliasearch'; const client = algoliasearch( functions.config().algolia.id as string, functions.config().algolia.key as string ); const postIndex = client.initIndex('posts'); export const savePostRecord = functions .region("asia-northeast1") .https.onCall((data) => { return postIndex.saveObject({ objectID: data.id, ...data }); }); export const deletePostRecord = functions .region("asia-northeast1") .https.onCall((data) => { return postIndex.deleteObject(data.postId); });
上記の関数をNext.jsから呼ぶことで渡したデータをAlgoliaレコードに反映することができます。
export const fns = getFunctions(app, 'asia-northeast1'); // レコード追加(更新)関数の呼び出し const savePostRecord = () => { const callable = httpsCallable(fns, 'savePostRecord'); await callable(postData); } // レコード削除関数の呼び出し const deletePostRecord = () => { const callable = httpsCallable(fns, 'deletePostRecord'); await callable({ postId: 'xxx' }); }
Cloud Functionsは実行速度が遅いのでこの関数をawait等で同期的に使う場合、数秒待つことになります。その代わりアクション終了後には確実に検索結果に反映されるようになります。より高速な反映を望む場合Next.js APIを使いましょう。
拡張機能を使ったトリガー同期
拡張機能を使う場合拡張機能の設定項目に沿って同期したいコレクションを指定するだけです。設定後は指定したFirestoreコレクションのデータが変更(追加、更新、削除)されるたびに自動的にAlgoliaにレコードが同期されます。ただし後述する長文対策がなされない点に注意しましょう。
また、Cloud Functionsは動作が遅いのでFirestoreに変更を加えてからレコードに反映されるまでに数秒のタイムラグがあります。
このタイムラグを解消したい場合Next.js APIを使うか、前述した呼び出し型関数を使ってください。
トリガー関数を自分で作成する
ここでは拡張機能を使わずに自分でトリガー関数を作成する方法を解説します。
functions/index.tsimport algoliasearch from 'algoliasearch'; const client = algoliasearch( functions.config().algolia.id as string, functions.config().algolia.key as string ); const postIndex = client.initIndex('posts'); export const syncPostToAlgolia = functions .region("asia-northeast1") .firestore.document(`posts/{postId}`) .onWrite((change, context) => { const newData = change.after.exists ? change.after.data() : null; // 削除時の処理 if (!newData) { return postIndex.deleteObject(context.params.postId); } // 追加、更新時の処理 return postIndex.saveObject({ objectID: context.params.postId, ...newData }); });
上記の関数を公開すると拡張機能同様Firestoreデータの更新に合わせて自動でドキュメントのデータがレコードに反映されるようになります。
レコードを分割して保存する
なぜ分割が必要なのか
Algoliaのレコードにはサイズ制限があります。平均10KB、レコード単体では最大100KBとありますが、Algoliaは精度やパフォーマンスの観点からレコードサイズを最小限にして分割することを推奨しているため、最大値は10KBと考えるべきでしょう。
10KBは文字数にすると5,000文字です。これは純粋な文章の文字数ではなくデータを構成するオブジェクトの構文({}や;)も含まれる数字で、長文の記事であれば超えてしまう文字数です。
また1つのレコードサイズが大きいと検索結果の取得も遅くなりますし、検索対象のテキストにノイズも入りやすいので結果の精度が下がります。
そこでAlgoliaはレコードサイズが大きくなる場合にはレコードを分割して保存することを推奨しています。できれば文章の見出し(セクション)で区切って分割するのが望ましいでしょう。どうしても難しい場合文字数で分割するなどがありますが、単語の途中で切れてしまうと正しく検索にヒットしなくなるため、せめて改行N個ごとなど、単語を欠損させないロジックで分割すべきです。
文章はマークダウンやHTML、あるいは文章構造のオブジェクトで保存されるケースが一般的かと思いますが、どのケースにおいてもJavaScriptの基本的な知識があれば長文を分割できます。
Twitterのようにそもそも投稿されるデータに文字数制限があり、長文を想定しなくていい場合レコード分割は不要です。Algoliaはレコードの数がコストに影響するため不必要にレコード分割をするのは避けましょう。
分割したレコードを一つにまとめる
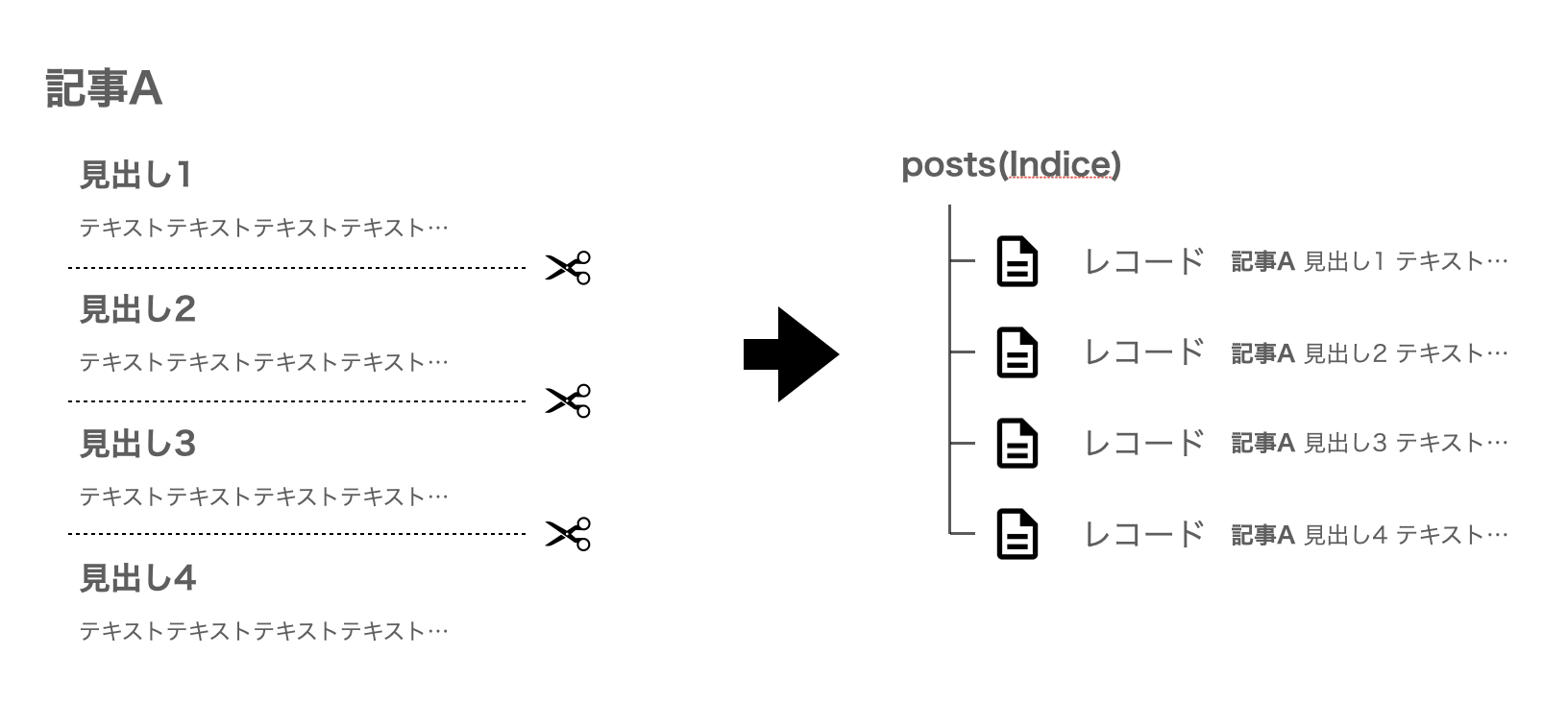
たとえば長文を含む記事Aを分割した場合、記事Aに該当するレコードがセクションごとに複数登録されることになります。仮に4つに分割したとします。検索結果はレコード単位で表示されるため、記事Aのタイトルに該当するキーワードを入力した際に、検索結果に記事Aのタイトルが4つ並ぶことになります。

これを解決するためにAlgoliaには distinct と呼ばれる機能が存在します。これにより同じ属性を持つレコードを一つのレコードとして扱うことができます。
ダッシュボードのIndice設定から "Deduplication and Grouping" を選択し、その中の "Distinct" を "true" に設定してください。次にまとめる条件となる属性を入力します。一般的にデータには固有のIDが含まれます。記事IDやユーザーIDなどで、id や uid などの名前で保持されているでしょう。それを "Attribute for Distinct" の欄に入力してください。こうすることで記事Aを分割した記事Aのレコードが複数あっても、 検索結果においては一つにまとまって表示されます。
分割レコードの実装
レコード追加、更新において実装の流れは以下です。
- 既存の分割レコードを一掃する
- 分割レコードを追加する
単体レコードの場合既存IDのレコードを上書きするだけなので都度既存のレコードを削除する必要はありませんが、分割レコードの場合不特定多数のレコードが存在しているため、新たに同じ記事のレコードを追加(または更新)する際は一旦該当記事にまつわる分割レコードを一掃する必要があります。
たとえば元々の記事は5段落あり5分割により5つのレコードが作られたとします。その後記事を更新することで3段落に減った場合、レコード数は3つになり2つの不要なレコードが生まれます。また、3つのレコードに関してもどのレコードをどの内容に更新するかを機械的に判断されるのが難しいため、その辺りの整合性を担保するために一旦既存の分割レコードをすべて削除する必要があります。
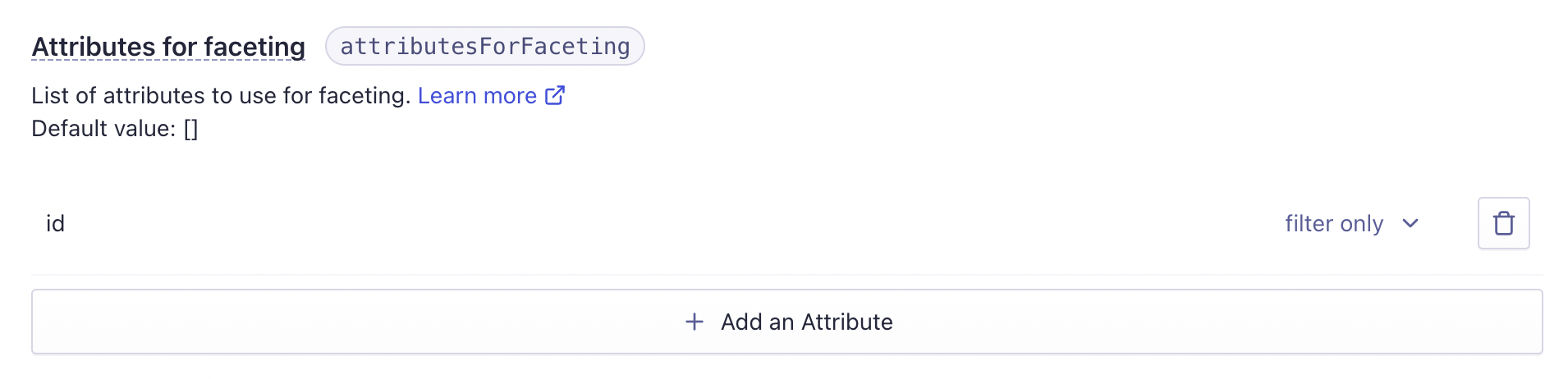
具体的には共通の記事IDを持つレコードを削除する実装を行います。そのために記事IDを "facet" に加え、フィルター条件として使えるようにしておく必要があります。
ダッシュボードの Indice 設定 > facets から "filter only" として "id" を指定しておきましょう。もちろん "uid" や "postId" などのキーで管理している場合はそれを指定してください。
以上を踏まえて実装例です。
// まずは既存の分割レコードを削除する postIndex.deleteBy({ filters: 'id:' + id, }) // 長文を定義(マークダウンの想定) const body = post.body; // 見出し単位で文字列を分割する const sections = body.split(/^#+ /gm); // 分割した数だけレコードのデータを複製する const objects = sections.filter(Boolean).map((section) => { return { ...post, // 分割レコードそれぞれに本文以外の共通のデータも含める body: section, }; }); // 複数のレコードを作成する postIndex.saveObjects(objects, { autoGenerateObjectIDIfNotExist: true, });
上記により以下のようなレコードが生成されます。
| objectID | id | title | body |
|---|---|---|---|
| ksi... | A | 記事A | 見出し1 はじめにこちらの解説をご覧くだ... |
| bps... | A | 記事A | 見出し2 次に注目いただきたいのが... |
| rax... | A | 記事A | 見出し3 いかがでしたか?最後にまとめで... |
それぞれのレコードが分割された本文(body)を持ちます。同時に、記事ID(id)やタイトルなど本文以外に関してはどのレコードも同じ内容を保持しています。レコード単体を表す"objectID"は autoGenerateObjectIDIfNotExist: true, のオプションにより自動生成されるためそれぞれのレコードが固有の "objectID" を持っています。
この中で "id" が同じであればそれは一つの記事として振る舞わせたいので、前述した "distinct" に "id" を指定しています。
分割レコードを削除する場合は前述の実装で事前にレコードを一掃している部分を引用するだけです。
postIndex.deleteBy({ filters: 'id:' + id, })
分割レコードに関する背景や詳細は公式ドキュメントを参照してください。
まとめ
- Algoliaのレコード管理はサーバーサイド(Next.js API or Cloud Functions)で行う
- Next.js API は早いがFirebase認証を自分で行う必要がある
- Cloud Functionsは認証が自動で行われるが動作が遅い
- Cloud Functionsで管理する場合呼び出し関数とトリガー関数の2パターンが存在する
- 長文を含むデータはレコードを分割して管理する
今回は基本的なレコード管理について解説しました。タグ、カテゴリ絞り込みやソート(並べ替え)に関しては別の記事で解説します。